13-12-2023
Introducció
A l’article anterior, vam analitzar les mètriques de New Relic per a trobar possibles colls d’ampolla en una aplicació web escrita en PHP emprant Symfony.
Vam veure que revisar i optimitzar les consultes a la base de dades podia ser un bon punt de partida. En aquest post, aplicarem diferents optimitzacions al codi i n’analitzarem els resultats.
Consultes a optimitzar
Hem optimitzat diferents tipus de consulta: afegint índexs o reescrivint-les. Per motius de brevetat, només en mostrarem tres exemples: dos que consisteixen a afegir un índex a una columna, i un altre que consisteix a reescriure una consulta. La resta d’optimitzacions que vam fer són semblants a aquestes.
Consultes repetitives
Hi havia algunes consultes que, tot i no tenir una penalització elevada en el rendiment, s’executaven a cada petició. Així doncs, encara que no suposaven un alentiment, era convenient optimitzar-les.
A les aplicacions mòbils, els usuaris es carreguen fent servir un token, tant pels usuaris finals com pels administradors. Aquest token s’envia en totes les peticions de l’API per a autenticar l’usuari, de manera que s’executa una consulta com aquesta1:
SELECT *
FROM `user`
WHERE token = ?;
Això no obstant, la columna token no tenia cap índex, de manera que havia de llegir totes les files. En conseqüència, a mesura que el nombre d’usuaris creixia, aquesta consulta es feia més lenta.
La solució consistia a afegir un índex a aquesta columna:
CREATE INDEX IDX_TOKEN ON `user` (token)
Teníem més casos similars a aquests, així que vam aplicar la mateixa solució a tots ells.
Consultes lentes
Ens vam trobar amb un altre cas de baix rendiment. Per a generar un codi QR per a l’usuari, l’aplicació feia una consulta a una taula amb l’històric de totes les comandes emprant un número de comanda. Aquest valor es desava emprant VARCHAR i es consultava amb una consulta com aquesta:
SELECT *
FROM `orders_log`
WHERE order_number = ?
Al principi, la consulta tenia un bon rendiment. Però, igual que en el cas anterior, a mesura que l’aplicació creixia i hi havia més files a aquesta taula —milions—, el rendiment baixava, perquè la base de dades havia d’escanejar totes les files a la taula.
Igual que en el cas anterior, vam afegir un índex a la columna order_number:
CREATE INDEX IDX_TOKEN ON `orders_log ` (order_number)
Reescriure una consulta
Per a validar usuaris, l’aplicació comprova una taula on hi ha tots els pagaments, anomenada orders —de la qual se’n deriva la taula orders_log. Tenia una columna de tipus TEXT on es persistien totes les dades relacionades d’un pagament en format JSON, perquè només estava pensada per com a històric.
Això no obstant, el desenvolupament de l’aplicació va tenir diverses iteracions, de manera que es va acabar fent consultes a aquest JSON, perquè era la manera més senzilla d’entregar valor a temps:
SELECT *
FROM `order`
WHERE data LIKE '%value%'
Com a la resta de casos, quan hi havia poques files a aquesta taula funcionava correctament. Però, a mesura que la taula s’omplia, la base de dades havia de llegir totes les files per a realitzar la consulta.
En aquest cas, donat que la columna és de tipus TEXT, no podem consultar els camps del JSON. Ni tampoc no podem afegir un índex simple com en els casos previs. Les columnes de tipus TEXT necessiten un full-text índex, però, per a aprofitar-lo, necessitem reescriure la consulta perquè sigui una cerca full-text, fent servir MATCH AGAINST.
Abans de reescriure la consulta, com que estàvem refactoritzant codi funcional, vam escriure un test funcional —un test que impacta la base de dades. Aquest test ens assegurava que els canvis que fèiem no impactava la lògica de negoci. Com que el codi feia servir arquitectura hexagonal amb el patró repositori, la consulta estava isolada en un mètode d’una classe. Així doncs, només vam haver d’escriure un test per a un mètode.
Amb el test a lloc, vam afegir l’índex FULLTEXT i vam reescriure la consulta:
CREATE FULLTEXT INDEX IDX_DATA ON `order` (data)
SELECT *
FROM `order`
WHERE MATCH (data) AGAINST (:parametrized_values IN BOOLEAN MODE)
Quan vam passar el test, vam tenir la certesa que la consulta era òptima i que seguia la lògica de domini esperada.
Resultats
Vam deployar aquests canvis en tres vegades, el 28 de juliol, l’1 d’agost i el 10 d’agost. Vam analitzar el rendiment després d’un dia sencer, perquè el pic de càrrega succeeix durant el dia.
A continuació revisarem alguns dels gràfics de New Relic després dels deploys, i analitzarem els nombres que obtenim en comparació.
Gràfics
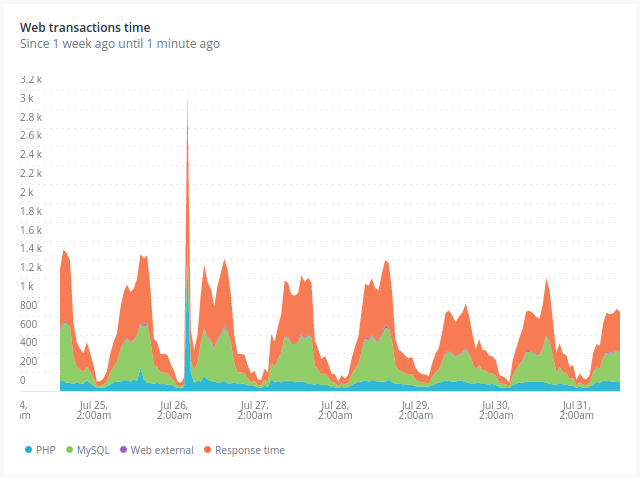
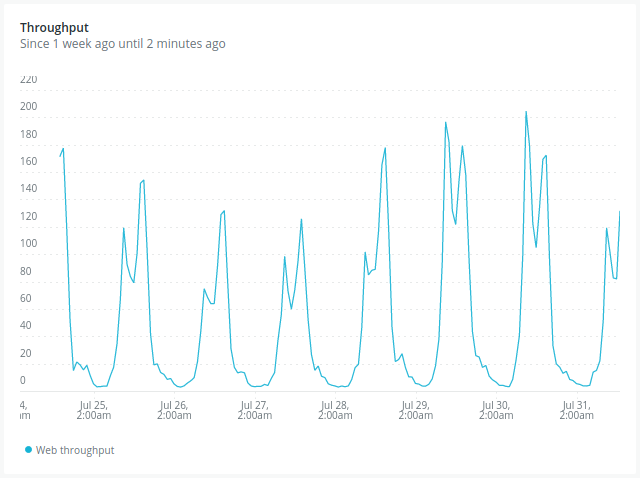
- Observem que el pic de càrrega és menor després del primer deploy.
- Complementàriament, el throughput és més gran: com menys temps triga la nostra aplicació a donar resposta, més peticions pot servir.
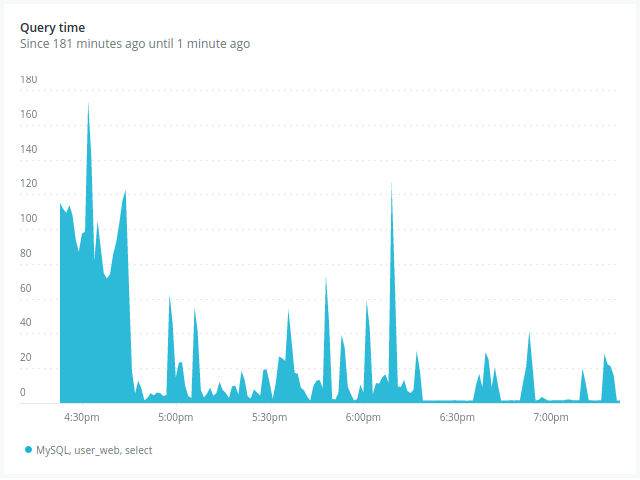
- Aquest és el gràfic de la consulta d’obtenir l’usuari pel token. Veiem que, després del deploy, el temps de consulta baixa abruptament. D’una mitjana del voltant de 100 ms, decreix a menys de 20 ms, amb alguns pics.
Anàlisi
Veiem a continuació l’anàlisi del temps de resposta, el throughput, l’ús de CPU i el temps de transacció de la base de dades, tres dies abans i tres dies després de cadascun dels deploys.
El temps de transacció de la base de dades és tan petit que no podem veure diferències als nombres, així que confiarem en els càlculs interns de New Relic per a mesurar-ne la diferència.
1er deploy
| Data | Temps de resposta (ms) | Throughput (%) | Ús de CPU (%) | Temps de transacció DB (ms) |
|---|---|---|---|---|
| 3 dies abans | 578.83 | 41.58 | 7.85 | 0.02 |
| 3 dies després | 443.56 | 59.7 | 8.73 | 0.02 |
| Diferència (%) | -22.7 | +43.69 | +11.13 | -10.27 |
2on deploy
| Data | Temps de resposta (ms) | Throughput (%) | Ús de CPU (%) | Temps de transacció DB (ms) |
|---|---|---|---|---|
| 3 dies abans | 448.34 | 58.33 | 8.98 | 0.02 |
| 3 dies després | 363.69 | 50.91 | 13.27 | 0.01 |
| Diferència (%) | -18.88 | -12.73 | +47.75 | -26.13 |
3er deploy
| Data | Temps de resposta (ms) | Throughput (%) | Ús de CPU (%) | Temps de transacció DB (ms) |
|---|---|---|---|---|
| 3 dies abans | 378.72 | 53.1 | 13.98 | 0.01 |
| 3 dies després | 328.41 | 60.6 | 14.01 | 0.01 |
| Diferència (%) | -13.28 | -14.12 | +0.21 | -7.79 |
Total
| Data | Temps de resposta (ms) | Throughput (%) | Ús de CPU (%) | Temps de transacció DB (ms) |
|---|---|---|---|---|
| Abans | 573.83 | 41.58 | 7.85 | 0.02 |
| Després | 328.41 | 60.6 | 14.01 | 0.01 |
| Diferència (%) | -57.23 | +45 | +22 | -44.19 |
Conclusions
Després de revisar els resultats, podem concloure que:
- Hem millorat el temps de resposta de l’aplicació en un 57%.
- Hem augmentat el throughput de l’aplicació en un 45%.
- Hem reduït el temps de transacció de la base de dades en un 44%.
Veiem que l’ús de la CPU ha augmentat un 22%, fins a un 14% d’ús total. Suposem que pot ser degut als nous índexs que hem afegit. Com que el seu valor no és alt, ho considerem acceptable.
Tot i que hem augmentat el rendiment de l’aplicació, encara tenim temps de resposta alts. Al següent article, revisarem com podem millorar el rendiment de l’aplicació encara més, centrant-nos en les peticions més lentes que en resten.
Resum
- Hem revisat com optimitzar consultes amb baix rendiment fent servir índexs.
- Hem reescrit una consulta que fa servir un índex
FULLTEXT. - Hem vist els resultats, concloent que hem millorat el rendiment de l’aplicació.
-
Per simplicitat, no mostrem la consulta real. ↩